In the last paragraph of my previous post ETL Becomes So Easy with Databricks and Delta Lake, I left a question about databricks Job Orchestration benefits and issues in ADF, I am going to introduce how do we solve it in this blog.

Firstly we all know that when we call a Databricks job (notebook) in ADF, it will automatically start a job cluster and terminated immediately when the job is finished. If we have multiple databricks notebooks need to be called in one pipeline, it will start multiple job clusters as below chart and will warm them up which ends up increasing cost of time.
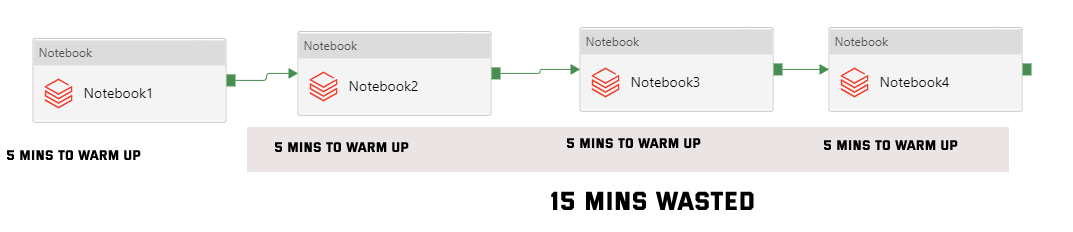
Can we reuse one cluster to run all these notebooks to kill those “warming up” time?
Yes, we can.
We can create a “master” notebook and using dbutils.notebook.run to call all the notebooks, I think most of you are familiar with this function as it can take parameters/arguments.
The dbutils.notebook.run command accepts three parameters:
- path: relative path to the executed notebook.
- timeout (in seconds): kill the notebook in case the execution time exceeds the given timeout.
- arguments: a dictionary of arguments that is passed to the executed notebook, must be implemented as widgets in the executed notebook.
E.g. dbutils.notebook.run("notebook-name", 60, {"argument": "data", "argument2": "data2", ...})
We can set up all these commands with sequence in one notebook if there are dependencies among them.
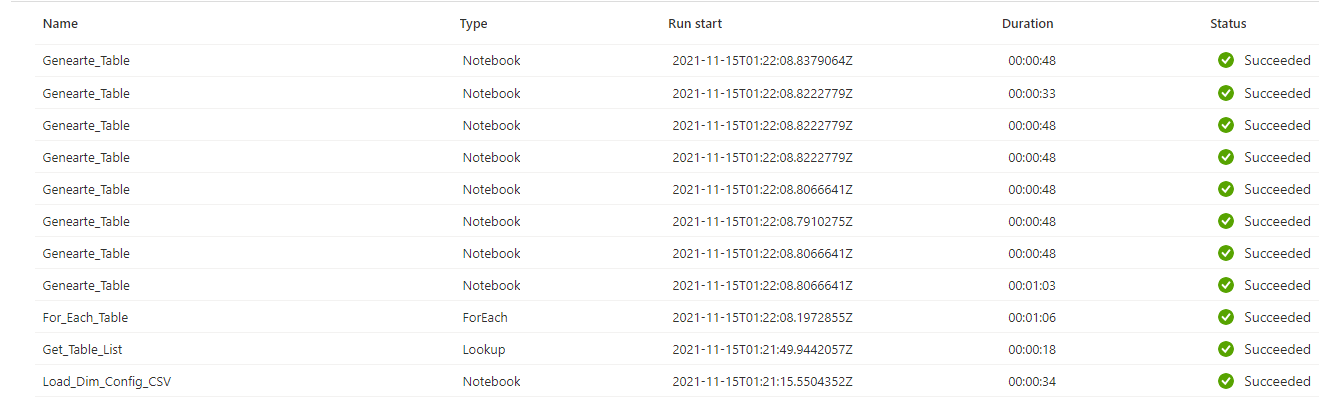
Now! There is a big benefit missing from ADF : parallel running jobs in Foreach Loop (see below screenshot)
Let’s handle this one.
Actually this is the key trick about this blog, I will post the code here for your reference.
import multiprocessing
from multiprocessing.pool import ThreadPool
pool = ThreadPool(8)
pool.map(lambda i:
dbutils.notebook.run("NotebookName", 600 , { "data" : i.data,\
"data1": i.data1,\
"data2": i.data2,\
...\
}),looplist)
Above code is functioning as Foreach Loop in ADF. It will pass the items from looplist to the notebook.run command as arguments, which is also the parameters (widgets) needed in the Notebookname.
The pool is set as 8 in above code, when you run it, it will be run the notebook with maximum 8 threads in parallel. If 3 of 8 jobs are finished, then it will automatically add another 3 jobs from the list to reach 8.
Please be aware that this number is not the bigger the better, as your job cluster’s computing resource limited, so adjust the number as you need.
Have Fun!
Eric